
Testing Synthetic Research in Practice
Lessons from using it to sharpen research design, not replace humans


I’ve spent the past few months watching synthetic research show up everywhere. Conference talks. LinkedIn posts. Case studies. Every time I saw it, I had the same reaction. This is going to be a disaster.
Not because synthetic research is inherently bad, but because I know what happens when a new tool promises efficiency. Someone uses it to skip the real work. Someone points to synthetic data and says “we don’t need to do user research anymore!”
I’ve cleaned up those messes before. I’ve been in the room when analytics replaced interviews, when surveys replaced conversations, when speed became more important than understanding. Every single time, the promise was “this will make research faster and cheaper.”
Every single time, we lost something that mattered.
So when synthetic research started gaining traction, I braced for the worst.
Then I looked around and realized this isn’t a future problem. This is already happening. 73% of market researchers have already tried synthetic responses. A third are using it regularly. Companies like Booking.com and Dollar Shave Club aren’t experimenting with it, they’re building it into their research practice.
The market moved without me.
And I had to ask myself: am I avoiding this because it’s actually bad, or am I avoiding it because I’m scared of what it means?
From Panic to Openness
Qualtrics asked if I’d be willing to test their synthetic audiences feature and write about the experience. My first reaction was panic. Was I going to try something like this? And how would it go?
Through the anxiety came another thought. How will I ever know if I don’t experience this?
I’ve been that person before. I was deeply suspicious of surveys when I was a qualitative purist. I thought unmoderated testing would never work. I resisted Jobs to be Done because I worried it would replace other frameworks I valued. Every time, my fear was the same, that this new thing will make my skills less valuable. Every time, I pushed these methods away and, ultimately, my career suffered.
I eventually tried the above methodologies and learned that they don’t replace what I do. They just give me a different way to approach certain problems.
Maybe synthetic research was the same.
So I said yes.
What I Needed to Understand First
Before I ran anything, I had to understand what I was actually testing and what synthetic really was because, trust me, there are a lot of different definitions out there.
Not all synthetic is AI randomly generating responses based on what it thinks humans might say. That’s what generic LLMs do when you ask them to “pretend to be a user.” Those fall apart fast. The responses are too agreeable, they lack demographic variation, they miss all the nuance that shows up in real research. It’s like having someone pat you on the back and tell you, “yes, that is the best product idea ever!”
I found that Qualtrics works differently. It’s trained on millions of actual human survey responses collected over 25+ years of research. When you ask it a question, it’s not guessing or fabricating. It’s looking at patterns across massive amounts of real human data and predicting what humans would likely say to that question.
This kind of synthetic data is model-generated data that’s built to mimic how a real audience might respond. Think of it as a way to explore likely patterns without running a full study with live participants. The key idea here is that mimicry isn’t the same thing as replication. In research, replication is tied to real people, real sessions, and repeating a study to see if the outcome holds. Synthetic data isn’t trying to do that. It isn’t claiming to recreate lived context or match what real participants would say word-for-word. It’s built to give you a fast, pattern-based preview of how a defined audience is likely to react, so you can learn, compare options, and move with more confidence before you invest in full fieldwork.
That difference matters. One is AI making stuff up. The other is AI drawing on what humans actually said when asked similar questions.
I still went in skeptical, but at least I understood I wasn’t testing random text generation. I was testing whether a model trained on real research data could show me something useful before I talked to a single person.
The Research Question
I picked a research question that felt like appropriate territory for testing synthetic: how do people make food decisions when they’re tired, stressed, and low on money?
This question type matched what synthetic is actually designed to handle. Synthetic performs well with perceptions, preferences, and intent-based questions.
As of right now, it doesn’t perform as well with past behaviors, detailed recall, and awareness questions. So I avoided anything like:
“Tell me about the last time you ordered takeout”
“Walk me through your typical dinner routine”
“How often do you meal prep?”
Those questions need memory. They need a biography. They’re asking people to reconstruct events and explain what happened. That’s not what synthetic is for. And, for me, that actually allowed a sigh of relief. Those questions above are the bread and butter of my deep, qualitative research and they aren’t what I would be asking a synthetic panel. I could save those for human-based research.
Instead, I focused on the mental state that shapes decisions:
What mindsets do people bring to food choices when they’re under pressure?
What kinds of friction stop people from deciding at all?
What does “good enough” mean when you’re exhausted and broke?
What would actually help in those moments?
These questions are about recognizing patterns, not recalling specific events. They focus on mental shortcuts and trade-offs.
WIth this, I built a 13-question survey. Every question had clear scenario framing, a specific cognitive task, and distinct answer choices that felt similar to those I’d create in a standard survey.
I kept the screening broad, just “are you involved in household food decisions?” You can screen with synthetic, you just can’t go hyper-niche, just like in real research. Screening for moms, millennials, pet owners, households of 3+, specific income brackets? Fine. Screening for “left-handed surgeons from Omaha?” That’s not happening. It’s the same as human research, the more niche you go, the harder it gets.
I launched the survey on a Wednesday morning.
By noon, I had 500 responses. How’s that for speed?
What The Data Actually Showed Me
I was met with a dashboard of data which, as a qualitative researcher, can sometimes feel overwhelming, but I took a deep breath and scrolled through the results.
Each question was broken down in several ways:
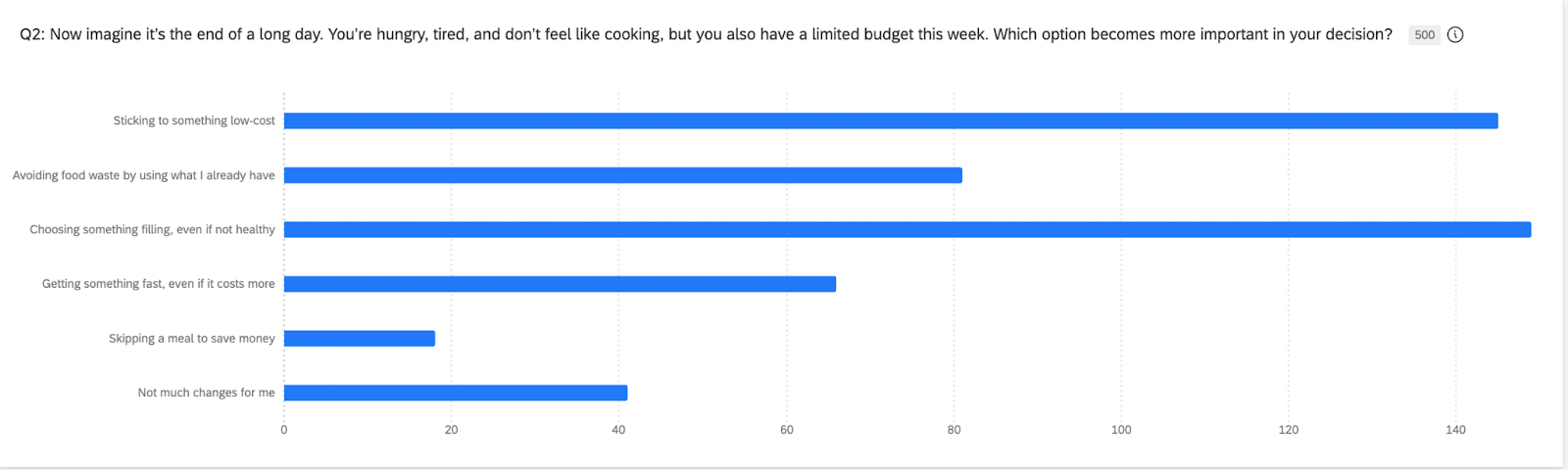
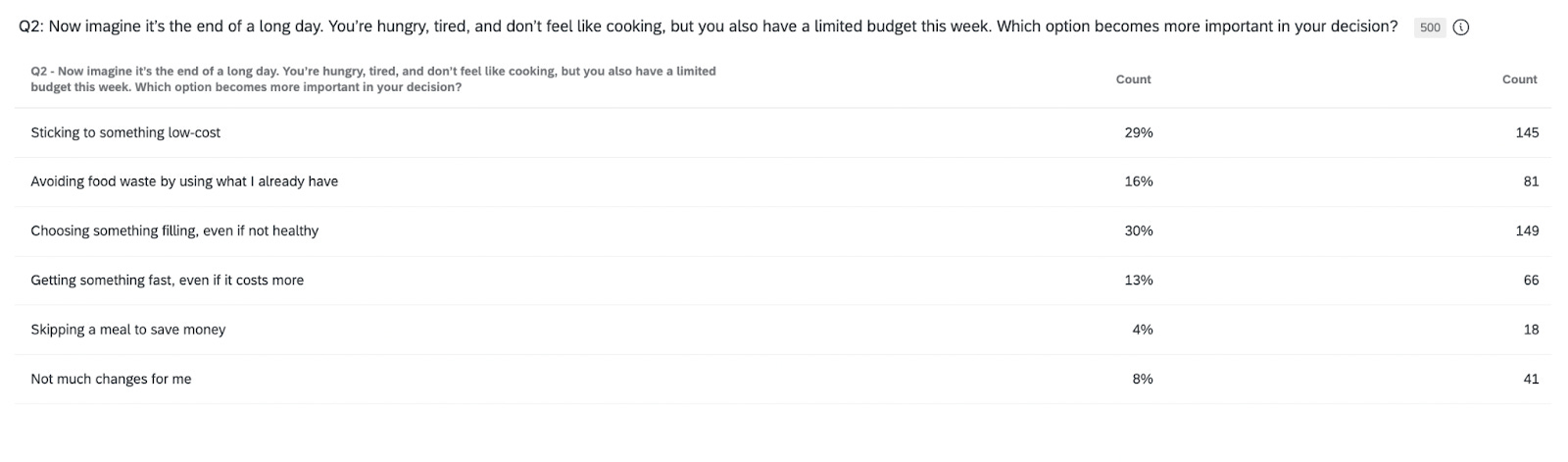
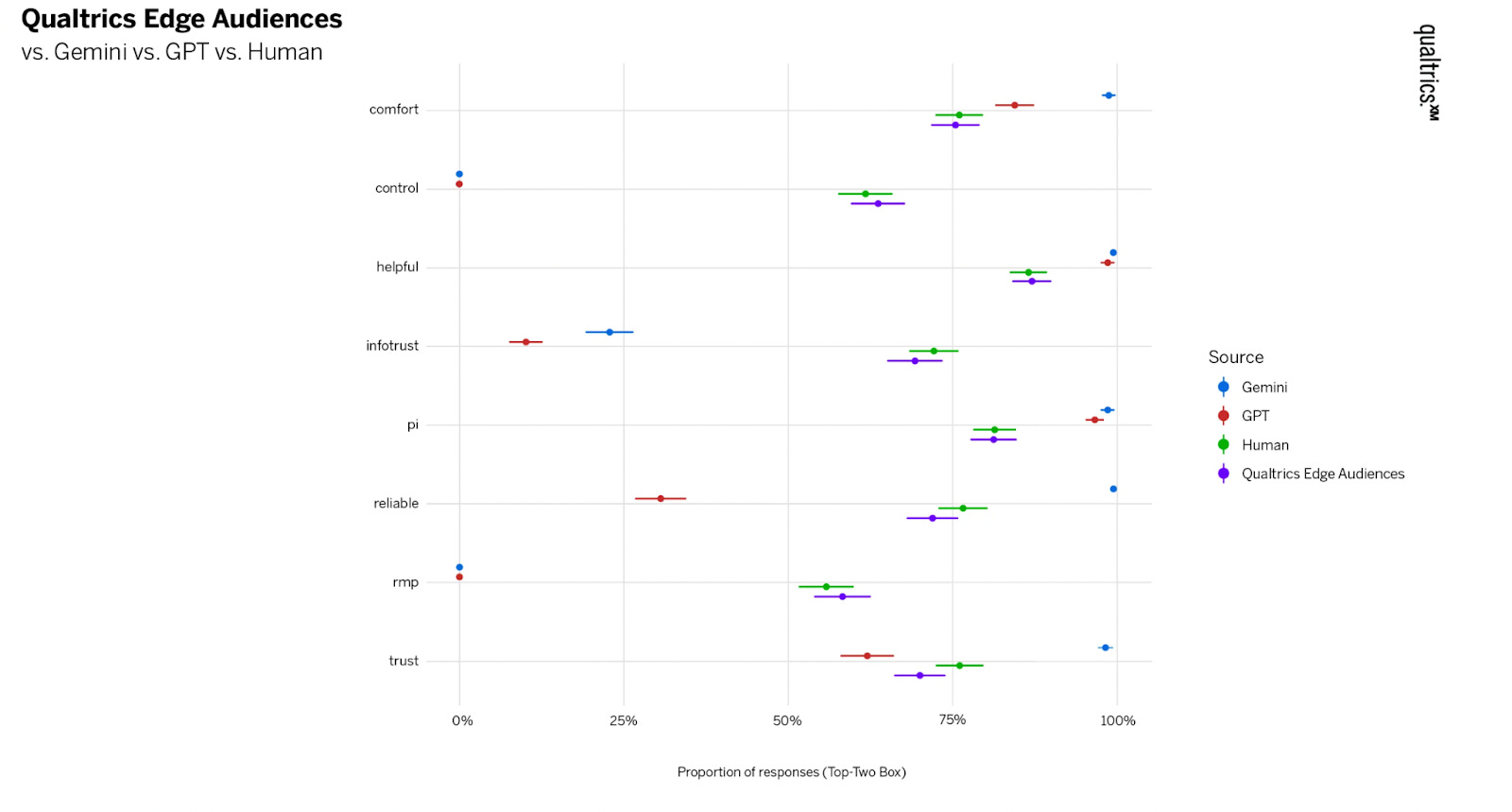
I really wanted to read the results as I would a traditional survey that I sent to real humans to fill out. The force was real with this. But, I took a step back first and really thought about how I would analyze these results. I took the first question: Now imagine it’s the end of a long day. You’re hungry, tired, and don’t feel like cooking, but you also have a limited budget this week. Which option becomes more important in your decision?
When I look at a synthetic-based chart like this, the goal isn’t to pretend I’m staring at “real behavior.” I was looking at a pattern the model thinks is likely when people are tired, hungry, short on time, and trying not to overspend. It’s a stress-test scenario. The value is in seeing how priorities reorder when the pressure dials up.
This is how I read the chart:
“Choosing something filling, even if not healthy” gets the strongest pull. In a depleted moment, people want to feel fed. Satiety beats ideals, beats convenience, beats health. It becomes the anchor. If I were running real sessions, this is where I’d expect the richer stories on what “filling” means, where they go, what they reach for, which shortcuts they trust.
“Sticking to something low-cost” sits right behind fullness. Tired or not, budget pressure stays in the picture. This gave me a directional hint that cost is a constraint people keep even when their energy is shot. In live research, I’d probe how they manage that tension. What counts as “low cost” in their mind? What crosses the line?
“Using what I already have” lands in the middle. It tracks with what real people say, that the intention is there, and it matters, but it’s easier to abandon when they’re drained. Synthetic data is giving me the shape of that trade-off, not the emotional story behind it.
“Getting something fast, even if it costs more” was lower that I expected. With a tight budget in the prompt, synthetic response showed a prioritization of price and fullness over speed. That doesn’t mean speed stops mattering for real people. It just means, in this hypothetical, it’s not the dominant driver.
“Skipping a meal to save money” sits at the bottom, but it’s not zero. That’s a cue for segmentation, not a headline. In real research, this is where I’d ask one of those beautiful, open-ended questions from above, “Walk me through the moment you decide not to eat. What’s happening right before that choice?”
“Not much changes for me” shows up in every study, real or synthetic. It’s the group with strong routines or fixed habits. They stick to their script regardless of energy or budget shifts.
Here are some other ideas I discovered while looking through the results.
The Cost-Versus-Speed Tension
One question asked: “When you’re low on time or energy, which of these factors usually has the biggest impact on your food choice?”
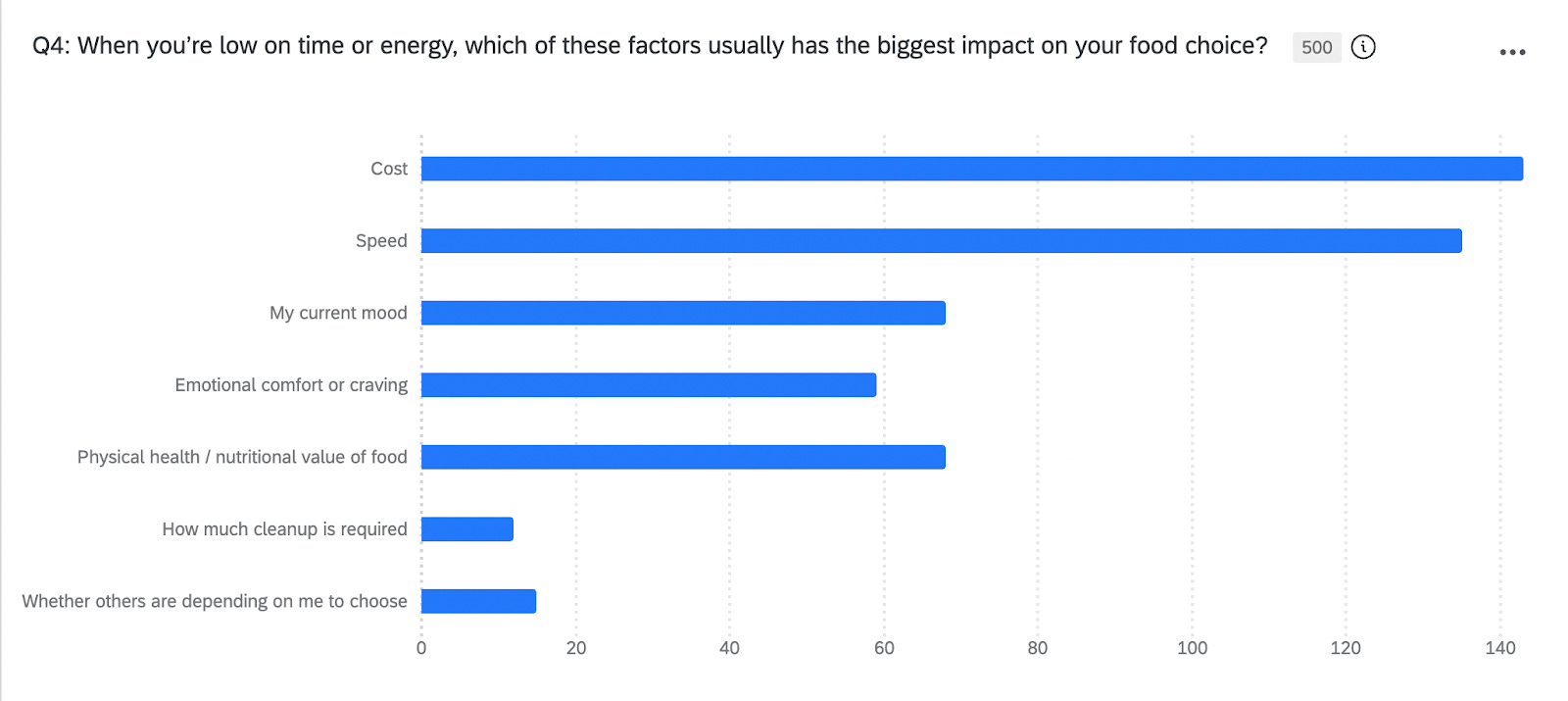
The results came back nearly split: “Cost” at 143 responses (29%) and “Speed” at 135 responses (27%).
Synthetic responses showed me that when people are tired and resource-constrained, cost and speed genuinely compete as decision drivers in human behavior. Neither factor dominates cleanly in the model’s prediction because neither factor dominates cleanly in real human decision-making. Results from the synthetic data said that humans are split on this because it’s a genuine dilemma they navigate.
I might not have seen that tension as clearly if I’d just written the question and jumped straight to interviews. I might have assumed one factor would always win. I might have designed my interview guide assuming cost would be the primary driver and missed the whole speed dimension.
This became a key area to explore in follow-up human research. When does cost win? When does speed win? What makes someone prioritize one over the other? The synthetic data had flagged where genuine decision-making complexity lives before I’d talked to anyone.
The Emotional Overwhelm Discovery
Another question asked: “What would make you completely give up on choosing food and go to bed without eating?”
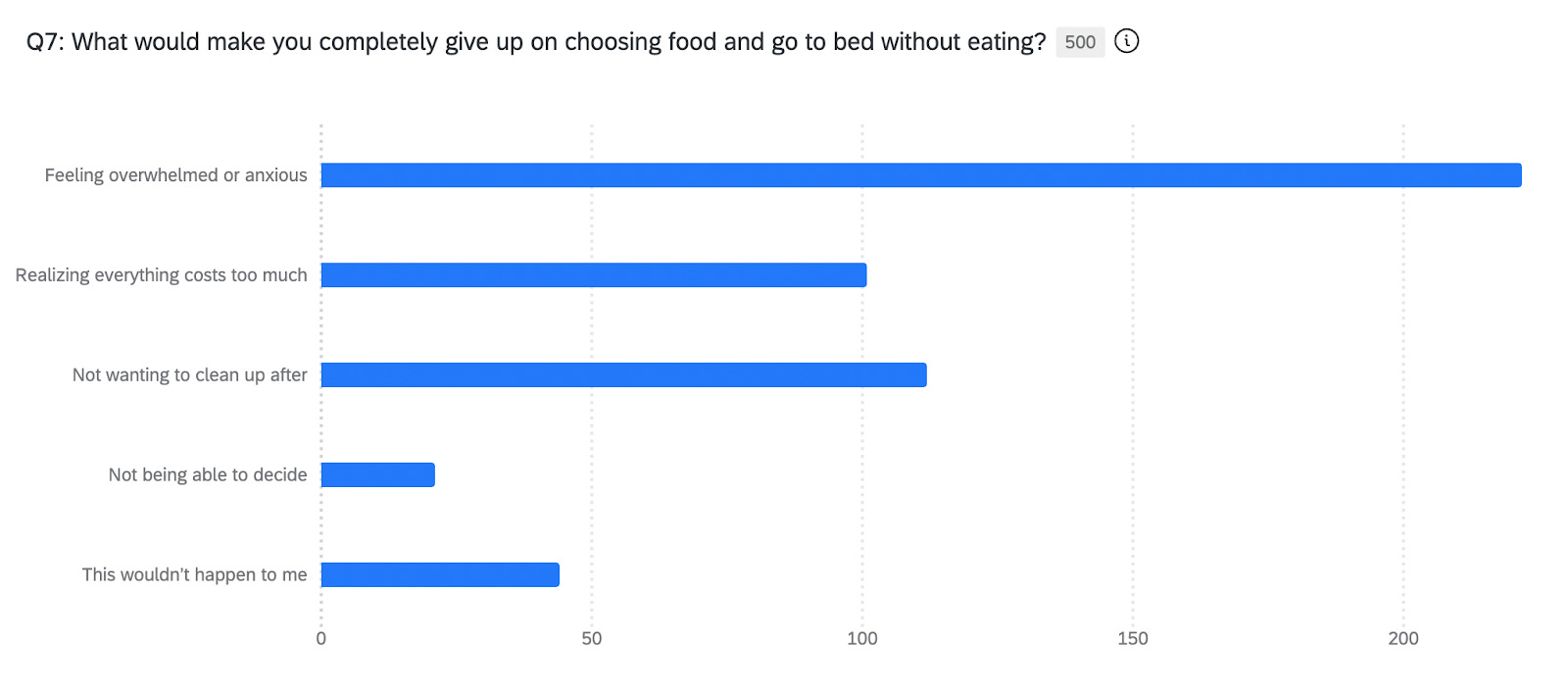
“Feeling overwhelmed or anxious” came back at 222 responses (44%), which was significantly higher than practical barriers like “not wanting to clean up after” (112 responses, 22%) or “realizing everything costs too much” (101 responses, 20%).
I’d designed that question thinking about practical constraints like money, effort, time. But the model highlighted emotional overwhelm as a much bigger driver of food decision abandonment than practical barriers.
I’d been thinking about this as a resource constraint problem. How do people choose food when money and time are limited? But the model was indicating that this is primarily an emotional regulation problem. People don’t give up because the barriers are too high, but they give up because making one more decision feels unbearable.
When I redesigned my interview guide for follow-up human research, I centered the emotional state instead of practical constraints. I made that the primary lens for exploration rather than treating it as a secondary factor.
The “Good Enough” Complexity
I asked: “Which of these feels most like a ‘good enough’ food decision when you’re tired, busy, and low on money?”
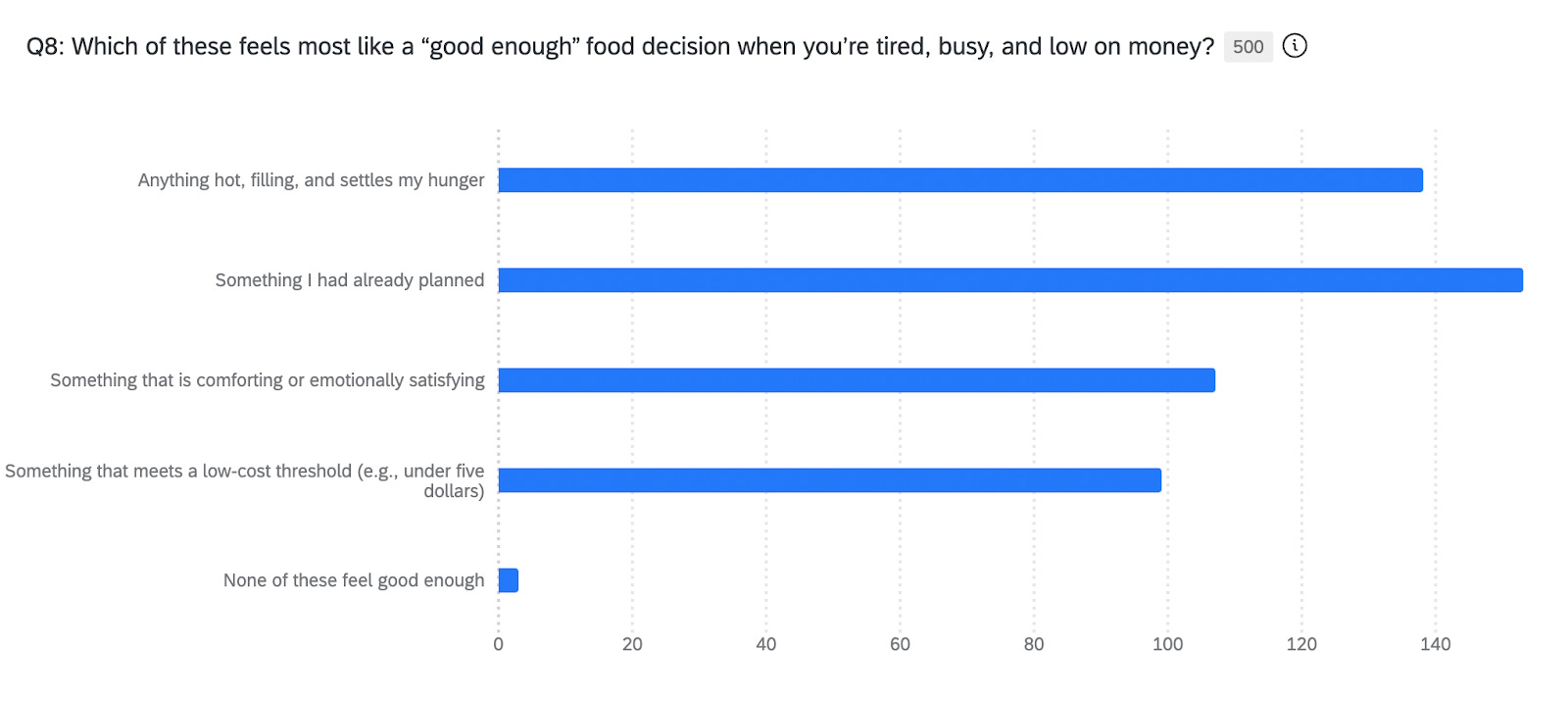
The distribution came back with no clear winner: “something I had already planned” (153 responses, 31%), “anything hot, filling, and settles my hunger” (138 responses, 28%), “something that is comforting or emotionally satisfying” (107 responses, 21%), “something that meets a low-cost threshold” (99 responses, 20%).
“Good enough” doesn’t mean one thing to humans. The model demonstrated that all of these definitions of “good enough” show up with roughly equal frequency, likely because they’re drawing on genuinely different frameworks depending on which resource (physical energy, emotional capacity, money, cognitive bandwidth) is most depleted in that specific moment.
When you’re physically depleted, “good enough” means something that fills you up and settles your hunger. When you’re emotionally exhausted, “good enough” means something that brings comfort. When you’re financially stressed, “good enough” means hitting a cost threshold. When you’re cognitively overloaded, “good enough” means not having to deviate from the plan you already made.
The flat distribution was the model telling me that I’d asked a question that collapses multiple real human patterns into one. When I designed follow-up human research, I split this into separate questions focused on physical needs, emotional needs, financial constraints, and cognitive load. That separation allowed for much clearer exploration of how different resource depletion states drive different definitions of “good enough.”
The synthetic data hadn’t just caught a poorly-worded question. It showed me I was conflating multiple human decision frameworks that needed to be understood separately.
While reviewing the results, something shifted. Not in a “this changes everything” kind of way, but in a “huh…this is actually interesting” kind of way. I started to see where this could fit into my workflow.
What This Actually Gave Me
After two days with the data, I had to ask: was this worth it?
I didn’t get finished, complete insights. I didn’t learn everything about how people make food decisions under stress. I wouldn’t feel comfortable walking into a meeting and presenting findings that would drive our next biggest product decision.
But I also didn’t waste anyone’s time. I didn’t recruit participants for a survey with broken logic. I didn’t schedule interviews based on assumptions that turned out to be wrong. I didn’t build a research plan around questions that collapsed multiple concepts.
Instead, I learned where the complexity was before talking to anyone. The cost-versus-speed split showed me there’s genuine tension in how people prioritize. The overwhelm spike showed me I’d underweighted emotional factors. The flat “good enough” distribution showed me I’d conflated multiple decision frameworks.
I redesigned my research approach with better questions. Instead of asking broadly about “good enough” decisions, I split it into questions about physical needs, emotional needs, and financial constraints. Instead of treating food decision abandonment as a practical problem, I centered on emotional regulation. Instead of assuming one factor would dominate the cost-versus-speed trade-off, I designed my interview guide to explore the tension.
I saved weeks of iteration time. If I’d skipped synthetic and gone straight to human research, I would have recruited eight people for pilot interviews, spent three sessions realizing my questions were off, spent three more sessions trying to figure out what I should have asked, and then recruited twelve more people for a second round with better questions. That’s 20 participants and three to four weeks of calendar time minimum. Synthetic compressed that learning cycle and helped to narrow the scope of a very broad study.
By the time I sat down with real participants, I wasn’t wondering if my questions made sense anymore. I was listening for the nuance synthetic can’t capture and the reasons why people make specific choices, with the emotional context around decisions, and the moments where behavior contradicts stated preferences.
I could focus on listening because I wasn’t worried about structure.
So, yes, to me this felt worth it.
A Note on Data Richness vs. Data Poorness
Data-rich organizations have massive amounts of customer data, years of research, thousands of completed studies. They’re not using synthetic because they have no data. They’re using it to drill deeper into the data they already have.
Data-poor organizations are the opposite. They are startups, small teams, companies entering new markets, researchers exploring completely new problem spaces. They don’t have years of existing research to draw from. They can’t afford to run massive studies. They need directional clarity fast, and they need it cheap.
That’s where synthetic becomes really interesting.
If you’re exploring a new market and you have zero data about how people in that space think, synthetic can give you initial pattern recognition based on what the model has seen across millions of responses in adjacent spaces. It’s not definitive and it’s not finished insight, but it’s enough to help you figure out which questions are worth asking humans and where the complexity might live.
Or take the “water cooler ask” scenario. Your VP drops by and asks, “Hey, do you think our customers would care about this feature?” You don’t have time to spin up a full study. You need directional sense in the next day or two. Synthetic can help you triage whether this is worth a real study, or can we deprioritize this?
Or feature prioritization when you have ten concepts and you need to narrow to three before you invest in validation research. Synthetic can help you screen fast without burning participant goodwill or budget on ideas that won’t make the cut.
Nobody’s replacing human research. They’re using synthetic to figure out where to focus their human research or to move faster with human research when they don’t have the luxury of time.
It’s triage. It’s prioritization. It’s the pre-work that helps you not waste resources on the wrong questions.
The Dance
For me, the most interesting use isn’t synthetic OR human. It’s the dance between them.
I could start with synthetic to map the territory quickly, like to see where tensions live, which concepts need exploration, what questions I’m not asking yet. Then bring in humans to understand the why behind those patterns. But it doesn’t stop there.
Sometimes human research surfaces something unexpected. Instead of just noting it and moving on, I could go back to synthetic to test whether that’s a broad pattern or an edge case specific to the five people I talked to. Then back to humans to dig into the nuance if it looks like a real pattern.
It’s not linear. It’s iterative.
With my food decision study, synthetic showed me the cost-versus-speed tension. I’d bring that to human interviews and discover, let’s say, that the tension resolves differently on weekdays versus weekends. I could go back to synthetic and test that hypothesis across a larger set of responses to see if it holds. Then return to humans with a more refined question about what drives the weekday-weekend difference.
Or the emotional overwhelm finding that synthetic flagged. I’d explore it with humans and learn that it’s specifically decision fatigue, not general stress. Back to synthetic to see if that distinction shows up in how people describe the overwhelm. Then back to humans to understand what actually helps with decision fatigue versus other types of stress.
The dance is what makes it work. Synthetic gives you speed and breadth to test hunches. Humans give you depth and context to understand what the patterns mean. You need both, and you need to know when to use which.
I didn’t see that coming. I thought I’d use synthetic once, pressure-test my questions, and move to humans. What I actually discovered is that the back-and-forth between them is where the real value sits.
What I’d Use This For
After this experience, I know exactly where synthetic fits in my practice.
Pre-research testing: Before I invest time and participant goodwill on a real survey, I can use synthetic to rehearse. Test if my questions make sense. See if different demographic groups might interpret things differently. Catch confusing wording or weak spots before anyone real has to deal with them. It’s like a dress rehearsal before opening night.
Follow-up exploration: After I collect real data and find something unexpected, I can use synthetic to explore “what if” scenarios without having to recruit a whole new round of participants. Test additional questions I forgot to include. Stretch my research budget by running quick follow-ups to probe areas where the human data pointed to something interesting but didn’t give me enough depth.
Concept screening and feature prioritization: When I have ten concepts and need to narrow to three before doing validation research, synthetic can help me screen fast. I’m not using it to make the final decision, but using it to figure out which three are worth the investment of real human research. Same with feature prioritization, I can quickly assess which features seem most valuable before committing resources to full validation.
The water cooler ask: When someone drops by with a question and I need directional sense-making fast, synthetic can help me triage. Is this worth a real study? Should we deprioritize this? Can I give them enough direction to make a next step without spinning up a whole research project?
Data-poor exploration: When I’m exploring a completely new problem space or market where I have zero existing research, synthetic can give me initial pattern recognition to help me figure out which questions are worth asking humans and where complexity might live.
What I absolutely wouldn’t use it for:
Answering research questions on its own without human validation
Understanding personal motivation, emotion, or lived context
Making high-stakes product decisions without any human input
Past behaviors, memory, or detailed recall questions
Anything where getting it wrong would hurt people
Replacing interviews, usability testing, or actual human research
The Fear I Started With
The fear of “is this going to replace me?” was never really about synthetic research. It was about value.
We worry that someone will decide our work isn’t necessary. That someone will find a faster, cheaper way to get “insights” and we’ll be left explaining why depth matters, why context matters, why you can’t replace human understanding with pattern recognition.
Using synthetic didn’t make that fear go away.
But it did clarify something for me. The work that matters, the listening, the probing, the synthesis of human stories into understanding, can’t be automated. A model trained on millions of survey responses can tell me where patterns exist. It can’t tell me why those patterns matter or what they mean for any individual person.
But the prep work like the question testing, the concept narrowing, the structural validation, can be faster. And when you speed up the parts that don’t require human voices, you create more space for the parts that do.
What I’d Tell Another Skeptical Researcher
If you’re reading this because someone asked you to try synthetic and you’re suspicious, I get it. I was there three months ago.
Keep your skepticism. Don’t let anyone tell you synthetic can replace human research. Don’t let anyone pressure you into treating AI-generated responses like they came from real people. But you can try it once with clear boundaries.
Pick a research question that’s attitudinal and forward-looking. Write 8-10 questions with clear scenarios and distinct options. Run synthetic. Look at the data for pattern flags and complexity signals, not finished insights.
Then ask yourself:
Did this help me design better questions?
Did it show me where complexity lives?
Did it save me from wasting participant time on bad design?
Did it help me figure out where to focus when I bring in humans?
If the answer is yes, you’ve found a tool that can make your human research stronger.
If the answer is no, you’ve confirmed your skepticism with evidence instead of assumptions.
Either way, you’ll know.
I’m still a qualitative researcher. I still need human voices. I still believe depth and context and lived experience are irreplaceable.
I just have one more tool for figuring out the right questions to ask before I involve the people who matter most.
This was a great read, thank you! I’ll admit I’ve been a bit wary of synthetic users too, but you’ve explained it in a way that actually makes the use cases feel practical and grounded. Definitely given me a lot to think about.
This is super insightful! The cost vs speed question is interesting, and it made me wonder what the reply would be for the distinct states (low on energy; low on time) and whether the cost statistic has anything to do with the previous questions (AI "memory" making the story make sense).
I love the suggested applications, I think we're all still figuring it out but that doesn't mean we should avoid these tools ❤️